Scrapers
Scrapers are a powerful tool in the DocIntel arsenal. They can be used to automatically collect information for you. Scrapers can be configured to fit your specific needs, and DocIntel comes with pre-defined scrapers to make your setup easy.
Basically, Scrapers are automated programs that collect information from the web, including from private websites or API. When you use a scraper, you don’t have to spend time manually copying and pasting data from various sources. Instead, you can program a scraper to do that for you. Scrapers can be configured in many different ways depending on what kind of data source you want to collect.
How to collect web pages?
To scrape web pages, such as blog post by cybersecurity companies, you need to configure the readability scraper. The readability scraper is a default scraper that uses Google Chrome to visit the website, extrac the content and generate the document to add into docintel.
To install the readability scraper, follow the steps:
- go to the administration menu on the left, and click on Scrapers.
- Click on the button install, on the top right
- Select Readability
- Enable the scraper
- You can optionally override some of the settings. For this use case, we do not recommend you to change the default values.
- Click install to finalize the setup
Now, DocIntel is configured to be able to process web urls. It means that DocIntel understands urls for the automated collection.
To collect a blog post and have it processed, follow the steps:
- Go to Documents, then Upload or submit in the left menu
- Put the URL of to the blog post in the “Provide URLs” text area
- Click Submit URLs
That’s it. The URL is now submitted, will be ingested in the background, by the newly created scraper, then be processed by the document analyzer, and last be available for you to review and register.
As we can see, the URL first appears in the ingestion list (below the pending list, as seen when you click on Documents then View pending in the left menu).

Then, when ingested by the scraper, the document is moved to the pending list.

Then, when analyzed, the document is ready for the registration process.
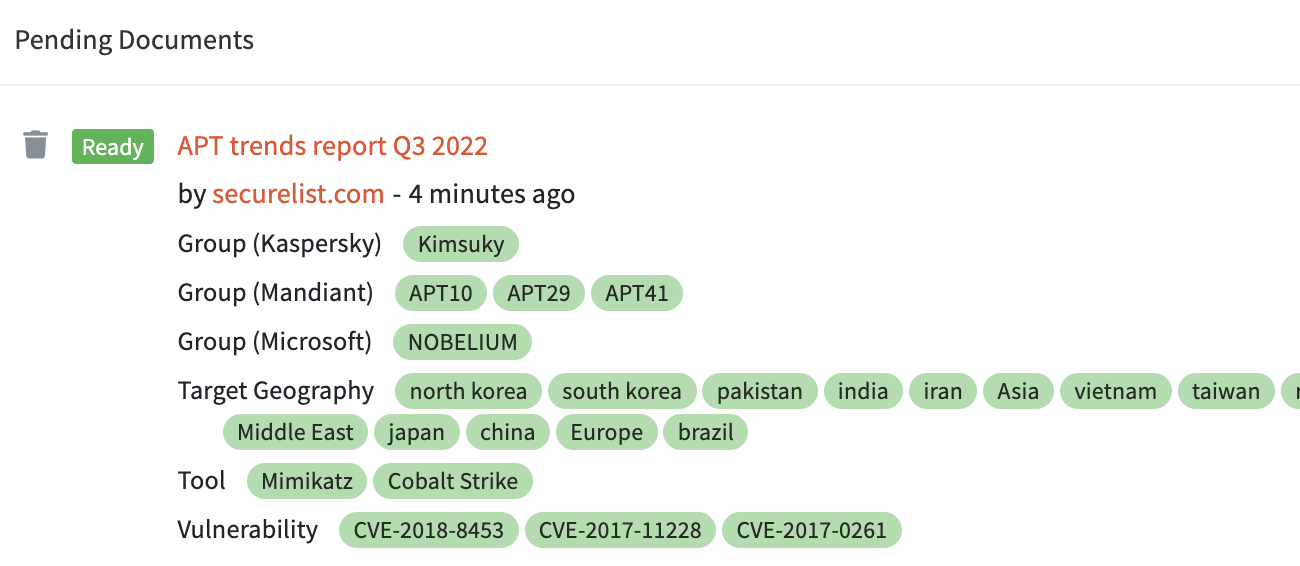
You can review the meta-data and extracted observables, and then enjoy the content now available in DocIntel.
